I like OOM(Object Oriented Model). Because our world is built by things. And we describe those things as noun, like sky, bird, hand, clothes. In OOD(Object Oriented Design), things are object/class entities. So there is the equation:
1
things == noun == entities (4.1.1)
Here, I will describe our system again. Clients will send message to our “Messager Service”. User will chat with someone. User can chat with many people in one chat room. Chatting is real-time. But if all clients of user are offline, system will send offline messages to one of user’s mobile client.
Why mobile client? Because web/pc client are hardly woke up. Emmm…Should we add a constraint? “User only use one client to login/chat.” Without this constraint, system should boradcast chat messages?
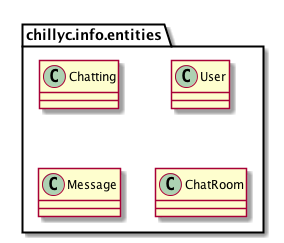
But here our key point is marking noun. I already marking them as “BOLD”. But client is not in “Server” rectangle in component diagram. I will draw client class diagram later.
Figure 4.1.1 init classes
4.2 Add relationship between entities
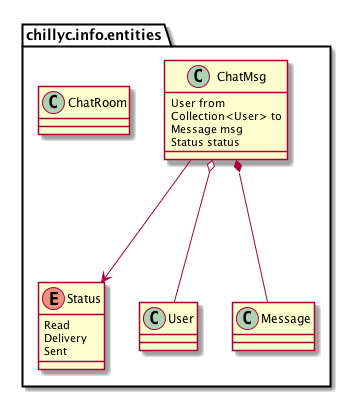
In Figure 4.1.1 Chatting class is the most important class. But Chatting means a chat message. So I change it to be “ChatMsg”. In ChatMsg class, there should be who send the message, who will receive it, and what’s the status of the message. Many users will receive the same ChatMsg Object. And one ChatMsg only contain one Message. If one ChatMsg is not exist, can the Message in it be exist? I think there should be strong relationship between Message and ChatMsg. And I call the relationship as “co-exist”. I draw solid diamond line between ChatMsg and Message. Other relationship with ChatMsg is not co-exist, but without User, the ChatMsg is meaningless. So I draw hollow diamond line between User and ChatMsg. Status is addition feature of ChatMsg. Without Status, we can not show chat status to our users. I draw arrow line between them. Now we draw Figure 4.2.1
Figure 4.2.1 init classes 2
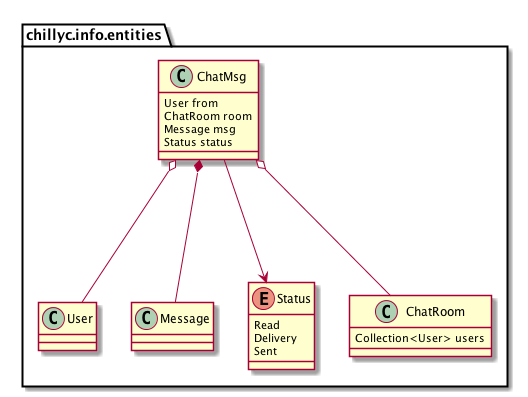
Emmm…Does ChatRoom relate with ChatMsg? Yes. We consider users chat with each other in one chat room. When one chat message generated, the system will send it to the users who are in the ChatRoom. So I put Collection into ChatRoom. So here it is:
Figure 4.2.2 init classes 3
4.3 Think twice
Here, another problem should be considered. If we join/leave ChatRoom, the users of ChatRoom will be changed. Can we see ChatMsg even if we leave the ChatRoom? If the status of ChatMsg is sent, and then someone join the chatroom, should the ChatMsg be delivered to him? Can new comer see old ChatMsgs?
There are many requirements:
new comer can see old chat messages. But someone quit the room, he can not see any chat messages be occurred in the room.
new comer can not see old chat messages. And someone quit the room, he will see nothing chat messages.
new comer can not see old chat messages. But even someone quit the room, he can see chat messages before he left in any time.
And there will be corresponding solutions too!
Do nothing, the class digram supports the requirements 1.
If ChatRoom is changed, we log it. So ChatRoom should contain version. The solution also supports requirement 1 and 3. But the performance of the system will be lower than 1 or 3.
We store Collection<User> in each ChatMsg Object, and Collection<User> is only the snapshot of ChatRoom. It seems there is no relationship between ChatMsg and ChatRoom. And it will cost more spaces (memory/disk) than 1 or 2.
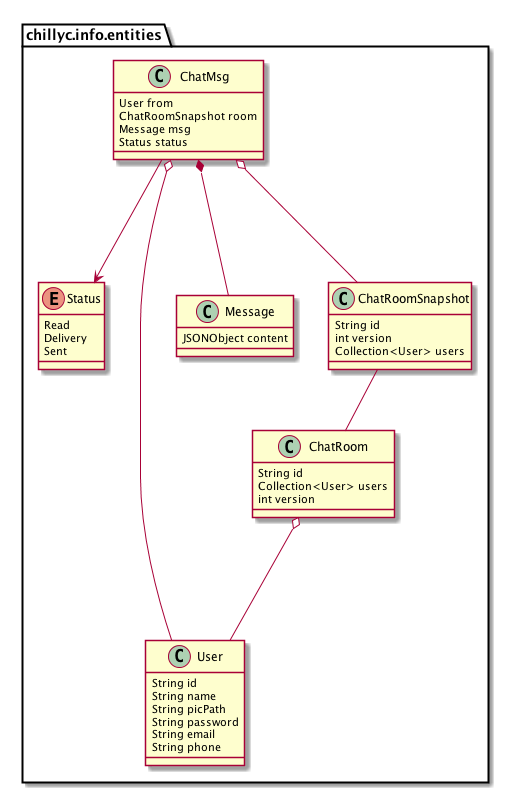
I will choose solution 2. The solution can adapt many requirements, and it stores the relationship between ChatRoom and ChatMsg. And I fill more field of Class Message and User. I call “ChatRoom history” as “ChatRoomSnapshot”. When ChatRoom is changing, the system will generate ChatRoomSnapshot to store old ChatRoom. The id of ChatRoomSnapshot and related ChatRoom must be the same. So the relationship between ChatRoom and ChatRoomSnapshot is weak. I just draw a line between them. In Message, I prefer JSONObject as its content.
Figure 4.3.1 init classes 4
All of above are our system “Server” entities. Is it enough? Those entities seem like static or immutable. And in component diagram, there are many components. Which component is related with the class diagram? The answer is none. Figure 4.3.1 only draw basic entities. Those entities will be used in each components. And now, I will draw details of each component, and “give life” to those entities.
Posted onEdited onInarchitectWord count in article: 6kReading time ≈5 mins.
Origin
I joined leetcode system design group to discuss how to design software. This is week3 topic:
Messenger service like What’s App with the following functionalities
One to One text messaging
Group Chat, Storage
Read/Delivery/Sent status
Gist:
We are having a conversation between two parties. A -> B. Think of this process. What happens and how do you explain to interviewer
Asynchronous - meaning, “You are on a flight and you receive messages once you land. So those messages were waiting some where!” (Hope you got it). How would you design it
Horizontal scaling, Load Balancer
For Read/Delivery/Sent status -> 3 way handshake protocol can give you an idea.
This is a good topic. I will try to design it.
Scenario
First of all, what’s the scenarios? The scenarios will correct my design. The scenario is in which way people use our software. So let’s think scenario first. The scenario should be atomic, and can not split into two or more scenarios. The scenario is a completed interaction. For example, The scenario like:
User A send message to the system.
The system send message to User B.
Step 1 or Step 2 is not a scenario. Step 1 with Step 2 is a completed scenario.
And our chat system will be like:
Figure 2.1 init system
Er…It’s too simple…So let’s write more scenarios:
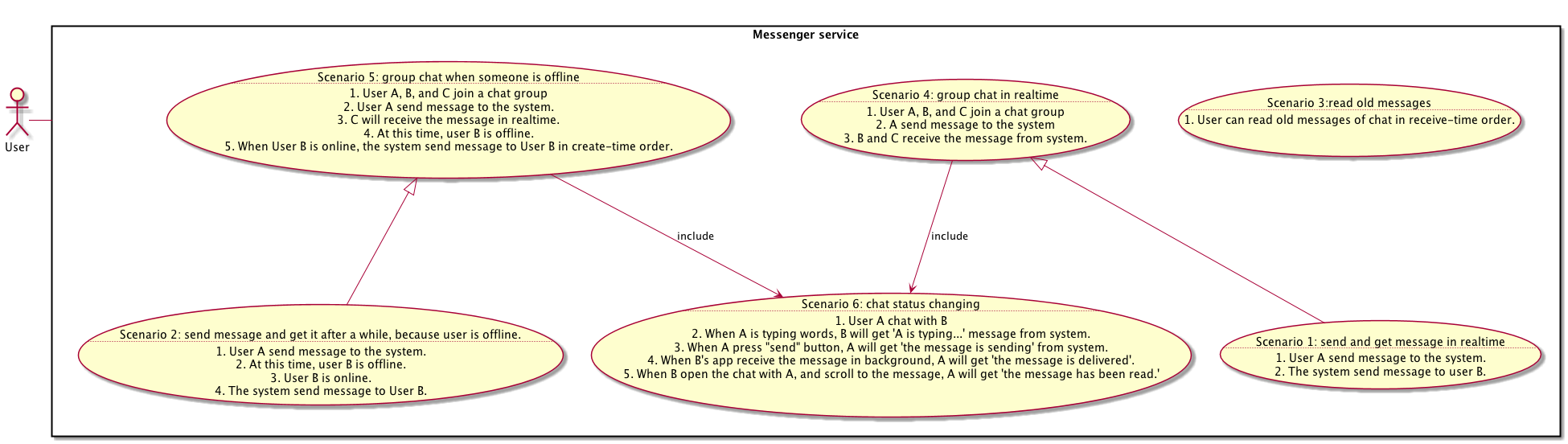
Scenario 1: send and get message in realtime
User A send message to the system.
The system send message to user B.
Scenario 2: send message and get it after a while, because user is offline.
User A send message to the system.
At this time, user B is offline.
User B is online.
The system send message to User B.
Scenario 3: read old messages
User can read old messages of chat in receive-time order.
Scenario 4: group chat in realtime
User A, B, and C join a chat group
A send message to the system
B and C receive the message from system.
Scenario 5: group chat when someone is offline
User A, B, and C join a chat group
User A send message to the system.
C will receive the message in realtime.
At this time, user B is offline.
When User B is online, the system send message to User B in create-time order.
Scenario 6: chat status changing
User A chat with B
When A is typing words, B will get “A is typing…” message from system.
When A press “send” button, A will get “the message is sending” from system.
When B’s app receive the message in background, A will get “the message is delivered”.
When B open the chat with A, and scroll to the message, A will get “the message has been read.”
Here, scenario 5 and 4 is similar to 2 and 1. So can we consider scenario 2 and 1 are group chat with only one person? Can I chat with myself? And there should be more scenarios be considered. For example:
User sign in
User sign up
User quit
Invite other user to use the app
Find a user
Add relationship with other user, family, friends, enemy, lover, couple, and so on. Others should comfire the relationship.
Break the relationship.
Rebuild the relationship with the same user. Er…Are you crazy? …Trust me, most of lovers will repeat break-rebuild relationship scenarios. If you don’t believe it, you must be younger than me.
Build a chat group, or invite other user one by one to join chat/group chat.
Exit a chat group, but can not exit one-one chat, unless breaking the relationship.
Type message with emoji, gif, png, voice, and other rich text.
Search old messages
Delete old messages.
Set/Show online/offline or other user status to one or more users.
Can we chat face to face?
Change user own info
In this article, we can not talk all above. It’s too complicated. I will only focus on group chat and chat status changing scenarios.
Figure 2.2 scenarios relationship
Like Figure 2.2 describles, one-one chat is a special case of group chat. So here use inherit arrow. The interaction of scenario 6 will be included from group chat scenarios. But scenario 3 is alone. If scenario 3 is discarded, our message service will be like “Snapchat”. And I use “User” actor instead of “User A” or “User B”. Why I always write a rectangle as “Messager service”? Because the rectangle warns us, our service has its own boundary! We will not consider other scenarios. If those scenarios inside of rectangle do not be implemented, our service is useless. And if you want to add more functionalities, the rectangle will be bigger and bigger. So thinking about your limit time and money, can you add more functionalities? The correct thing is creating worked well service, notwriting piles and piles of functionalities. Mmmmm…sound like: I use your “Messager service”, will you add “beautify photo”? NO!!!
How to design?
Seems like we always talk about how user use our messager service. Er…Correct! So here I will write something about how to design it. I don’t know how to build the system. I only knows there should be a client and a server…So like that:
Figure 3.1 init components
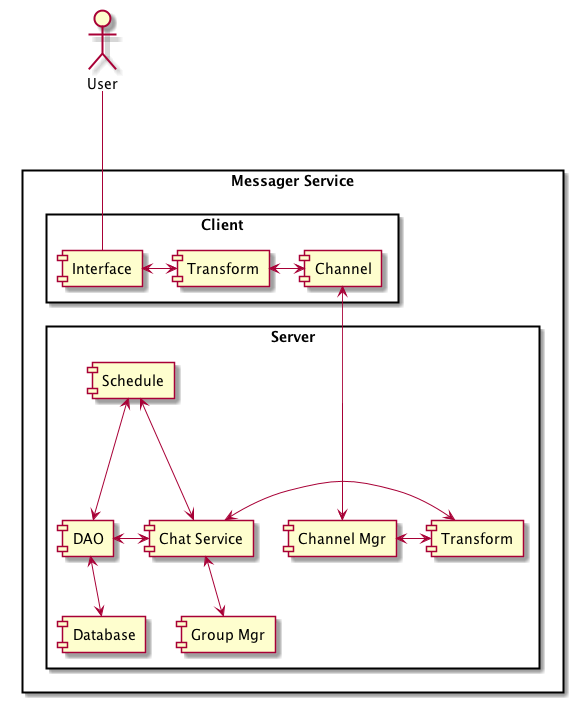
Now, we have first components diagram. Let’s do more thinking. If we store data, we will have database. If we connect with others, there should have a channel mananger. My chat groups should be controlled by group manager. If some user is offline, can we send offline message to them by APNS? Adding schedule component for sending message to offline user is a good idea. There should have a component for transforming “chat message” to service data, and doing reverse. And another component called “chat service” controls all component to work togather.
Figure 3.2 decompose components
In Figure 3.2, I decompose “Client” into “Interface”, “Transform” and “Channel”, and decompose “Server” into other small components. How to use line to connect those components? The answer is if the connection between components exists, connecting them. It’s nosense!! And another way to deal with the connections is following data flows. In Message services, there exists at least two data flows.
User -> Client Interface -> Transform message to bytes/data -> send to Channel -> Server Channel Mgr receive bytes/data -> Transfrom into server data -> according to data, pull group data from Group Mgr and store message into Database.
According to group info, sending message to other group members -> Transfrom server data into bytes -> send to Channel Mgr -> delivery message to Client Channel -> Transform bytes to message -> display message to User.
Schedule reading what cannot be deliveried -> send message through Chat Service -> Transfrom server data into bytes …
Er…Can we connect Group Mgr with DAO? YES. One point is you can change all diagrams in any time. And another point is, if you don’t draw line between Group Mgr and DAO, you can implement the system as well. For example,
we can store group info into files
we use Chat Service as proxy to store group info. Chat Service will call DAO to store group info, if chat exist. If the group members are all silence, the group will be destroyed after a while.
Is there a formal way to draw those components and lines? NO. This is why the software is attractive. Every software is artwork. Do you remember your first program? Always print: “Hello World!” It’s boring! Can we make the world different?
End? No. I will write how to decompose conponent into classes later.